What is CloudQuery Cloud
CloudQuery Cloud is currently in beta. Not all functionality may be available. See the limitations section below.
CloudQuery Cloud is a great way to get started with CloudQuery and syncing data from source to destination without the need to deploy your own infrastructure. You only need to select a source and destination plugin and CloudQuery will take care of the rest.
With CloudQuery Cloud, you can:
- Sync data from any CloudQuery official source (opens in a new tab) to any CloudQuery official destination (opens in a new tab).
- Schedule syncs to run at regular intervals.
- Monitor syncs and view logs in the CloudQuery Cloud dashboard.
- Use the CloudQuery Cloud API to manage the syncs and connect to your other data pipelines.
Prerequisites
To run a sync, you will need to know where you want to store the data (a database or a data warehouse), and what sources you want CloduQuery to connect to and sync data from.
If you don't have a database available, we recommend that you try a managed service such as Neon (opens in a new tab), ClickHouse (opens in a new tab), or MongoDB Atlas (opens in a new tab). All offer a free tier or a free trial sufficient for your initial experiments.
Creating Your First Sync
First, head to CloudQuery Cloud (opens in a new tab) and sign up for an account. After the sign up, you will be asked to specify team name. Team name is important if you later decide to create your own plugins. Please note that the team name cannot be changed later.
After you have signed up and created a team, you can create your first sync from the Syncs tab.
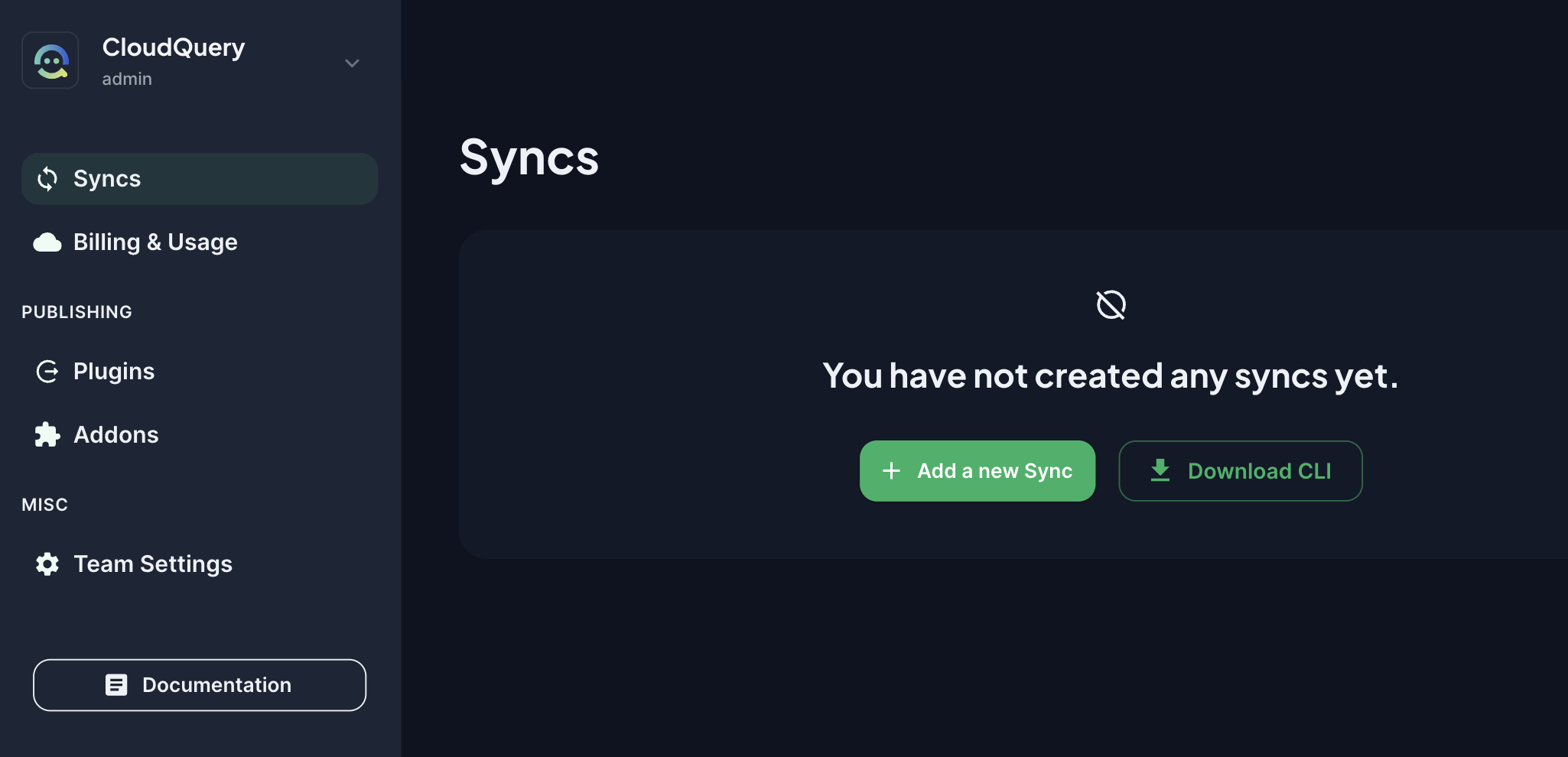
Clicking the button will start a wizard that will walk you through the whole process.
Configure a Destination
First, you need to configure where the data will be stored. Choose a CloudQuery plugin from the list of available destinations. PostgreSQL is a good choice for most use cases and is usually the easiest to get started with.
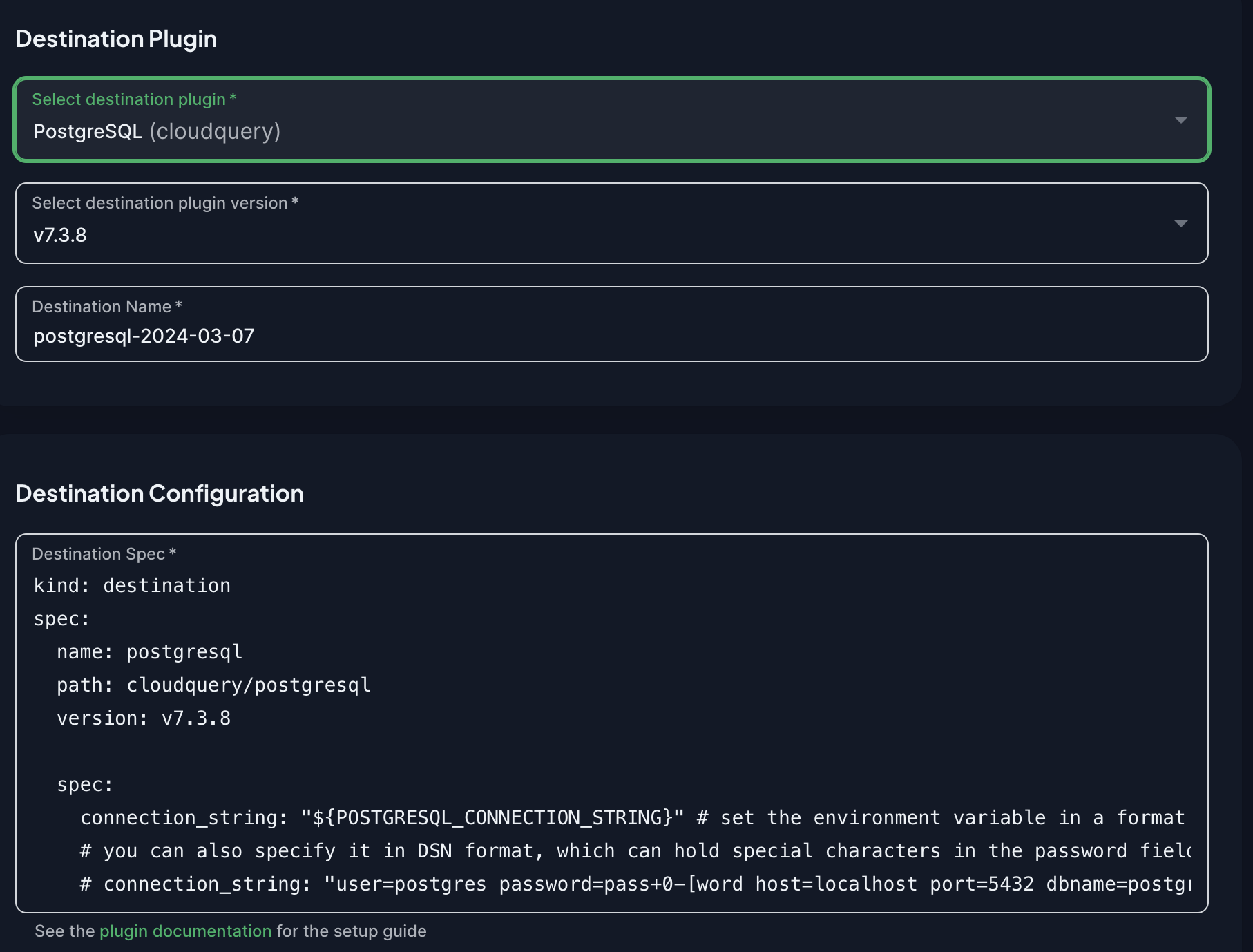
In the screenshot above, you see different configuration options for the PostgreSQL destination plugin. You can select a version and provide the detailed configuration in the YML format for the plugin. The YML format and the specification is the same as the one you would use in the self-hosted syncs and you can learn about the details and all the different options in the individual plugin documentation.
For a sync to a cloud-based PostgreSQL database, you will only need to provide a connection string. The YML configuration for the destination plugin references the connection string using an environment variable:
connection_string: "${POSTGRESQL_CONNECTION_STRING}"To provide the value for the environment variable, set it in the secrets section below:
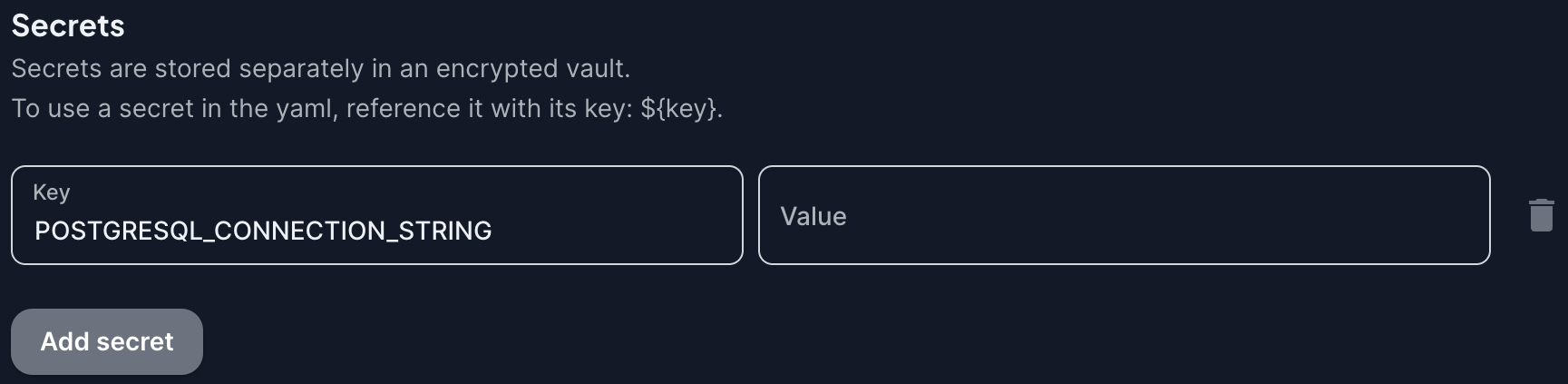
Using the secrets section is the recommended way to provide sensitive information such as connection strings. Do not hardcode sensitive information in the YML configuration as the configuration is stored in plaintext in the CloudQuery Cloud database and may be exposed in logs.
Click Continue to proceed to the next step.
Configure a Source
Next, configure how CloudQuery should connect to the source of your data. Select a source plugin from the dropdown.
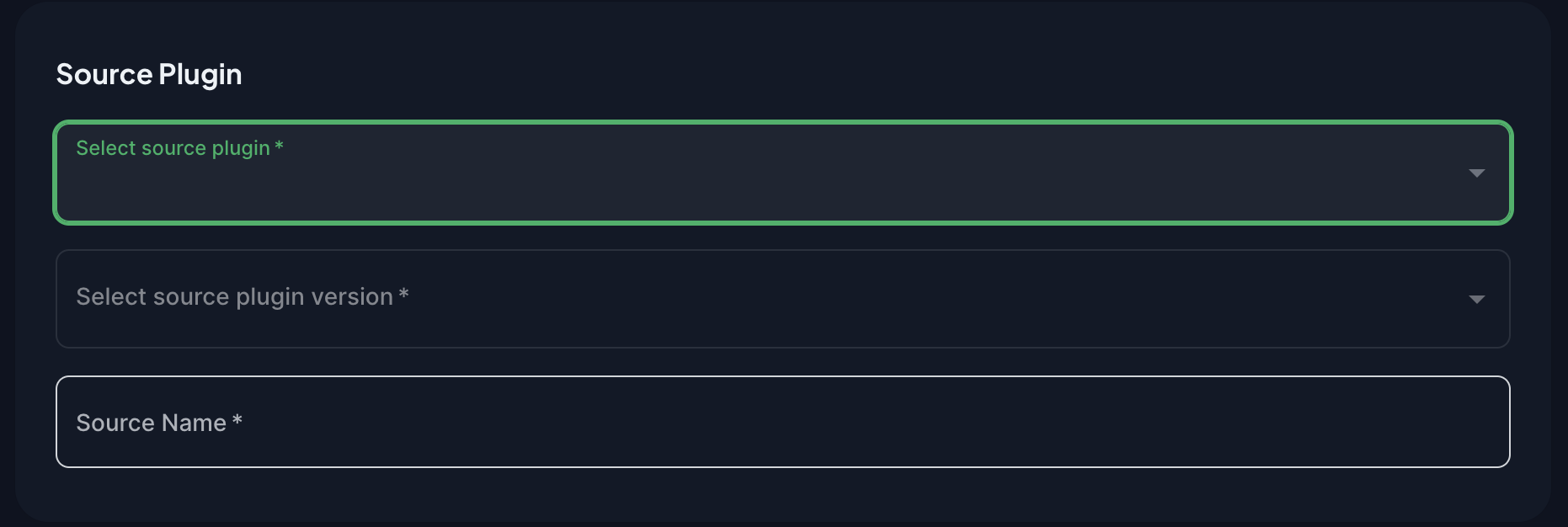
Once you select your source plugin, its example YML configuration will load:
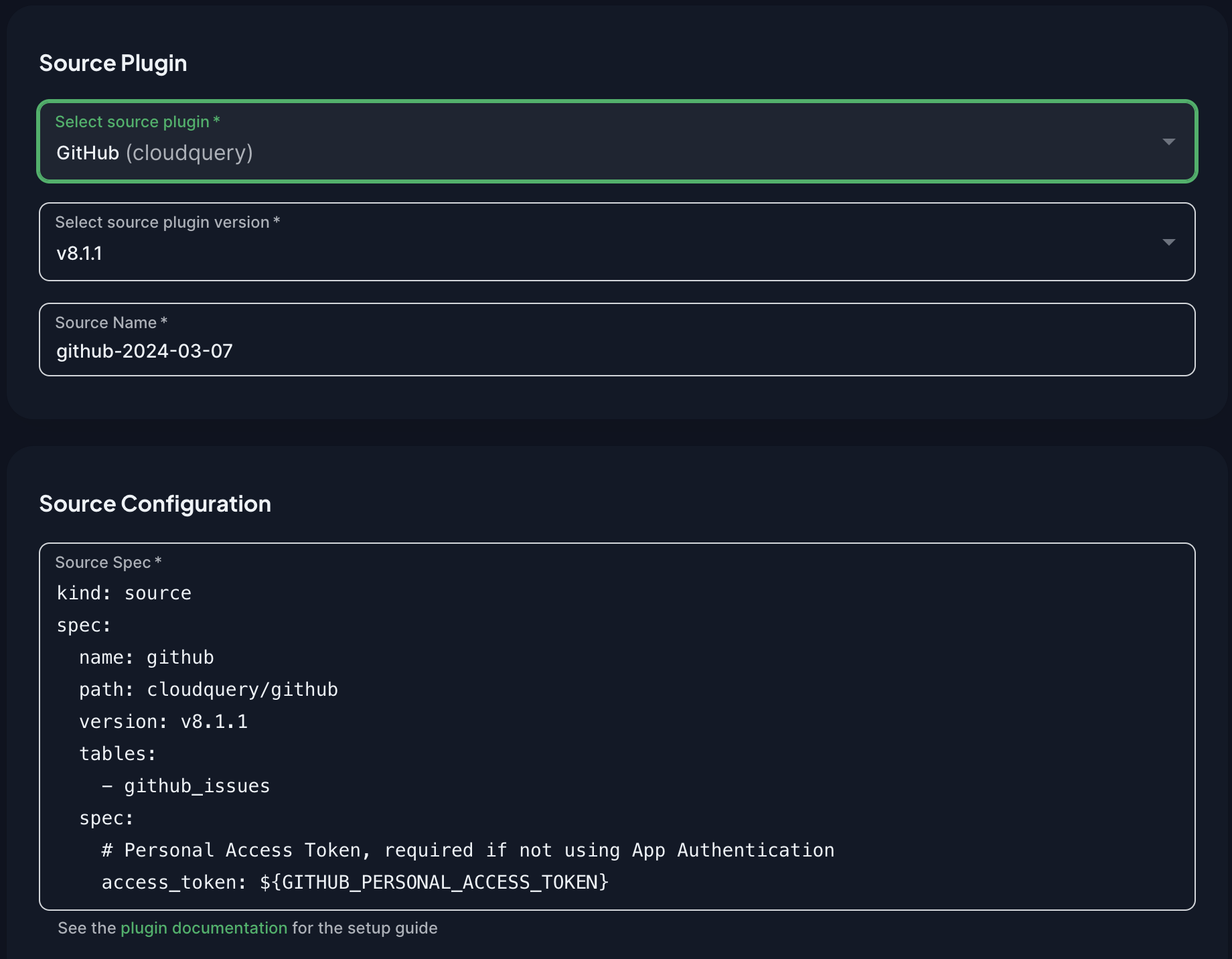
Again, see the plugin documentation for details on the configuration options.
For most sources, you will need to provide an API key, access token, or a connection string. You can provide these in the secrets section as you did for the destination plugin.
Click Continue to proceed to the next step.
Configure Sync Options and Schedule
On the last page, you can configure the sync name, schedule, and allocated resources.
Schedule
You can configure the syncs to run Daily, Weekly, Monthly, or at a custom schedule using the cron syntax.
If you configure syncs to run Daily, they will run at midnight every day. Weekly syncs will run at midnight on Mondays, and monthly syncs will run at midnight on the first day of each month (all in UTC timezone).
Allocated Resources
You can choose to allocate vCPU and vRAM resources. Some plugins may need more vRAM or vCPU to run efficiently. The default values are usually sufficient for most use cases.
Run the Sync
After you have configured the sync options, you can either save the sync and run it immediately, or you can schedule it. If you run it immediately, the next execution will happen at the specified schedule.
When the sync is running, you can observe the execution as it happens in the Sync Run Details view. The data is being streamed to your database during this process.
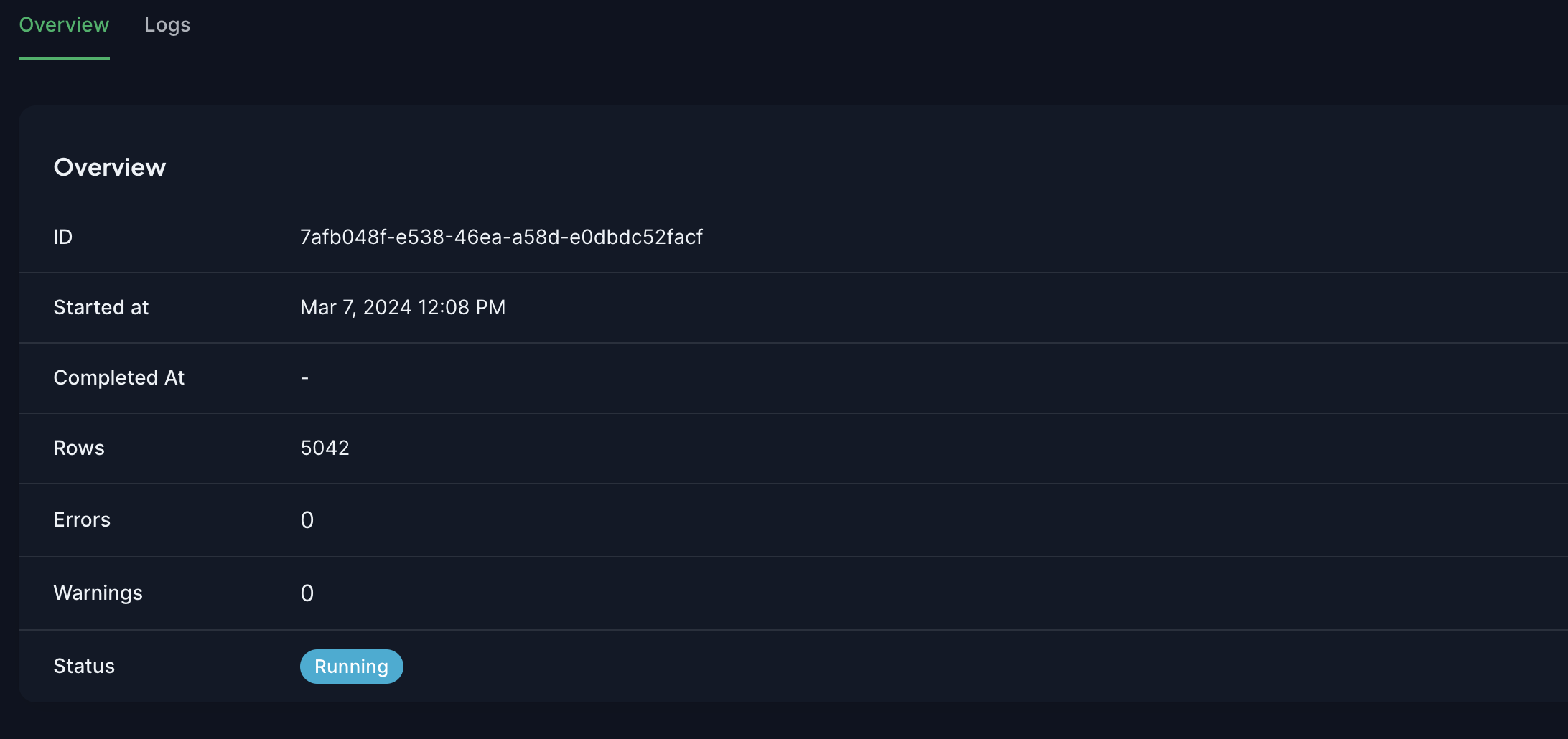
Errors and warnings are displayed in the logs section. Only errors that prevent the full sync are considered as breaking. This means that a sync is considered successful even if it has some errors or warnings due to the fact that some tables may not be accessible.
API Access
Cloud syncs can be controlled using API. To use the API, you will need to generate an API key. For the list of available endpoints, see our API Reference (opens in a new tab).
Limitations of Cloud Syncs Compared to Self-hosted
- Backend Options are not available. This is a limitation during beta phase and will be removed before the general availability.
- Docker-based plugins cannot be used with CloudQuery Cloud. This is a limitation during beta phase and will be removed before the general availability.
- Not all authentication mechanisms that work on self-hosted syncs work with CloudQuery Cloud. We are continuously adding support for more authentication mechanisms.
- Community and custom plugins cannot be used with CloudQuery Cloud. This is by design and will not be removed in the near future.
